Fine-Tuning in MLRun: How to Get Started
How to fine tune an existing LLM quickly and easily with MLRun, with two practical hands-on examples.


Fine-tuning is the practice of training a pre-existing AI model on new, focused data. By enhancing the model’s domain-specific performance, organizations can make their LLMs production-ready and turn their generative AI applications into a competitive differentiator. In this blog, we’ll explore how MLRun simplifies and accelerates fine-tuning workflows with two practical, hands-on examples, which you can easily follow and replicate.
Fine-tuning is a machine learning method where a pre-trained model is further trained on a specialized dataset to adapt it to specific tasks or domains. Fine-tuning involves modifying the model’s internal parameters based on new data (rather than the model’s output), to enhance its performance for particular applications. This makes the model more specialized for specific tasks and valuable for business use cases.
Fine-tuning is considered a resource-efficient method because it leverages pre-trained models, rather than having to train a new model from scratch. However, resources for the fine-tuning process itself need to be managed efficiently to ensure cost-effectiveness.
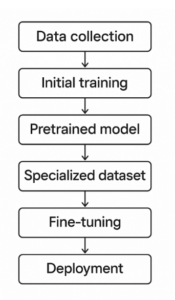
In AI pipelines, fine-tuning takes place in the development pipelines, after data is collected and initial models are trained. Before deploying the model, it’s recommended to evaluate the fine-tuned model and ensure it meets required standards.
MLRun provides pre-made functions that will tune, track the model/dataset, dynamically allocate GPUs in a K8s cluster, etc. Then, MLRun can be used to serve the newly fine tuned model at an endpoint. MLRun can then be used to monitor the model over time with custom metrics/guardrails (see example #1 below).
You can find these functions in these resources. Below we show examples of how to fine-tune with MLRun. There are also more demos and resources in the end:
Let’s take a look at two examples of how to fine-tune with MLRun. Follow along with the tutorials on your own:
Fine-tuning can take place after an application is developed and in the monitoring phase. By observing how the model performs in production, such as how it handles edge cases, evolving user behavior, or domain-specific nuance, teams can fine-tune the model to correct drift, improve accuracy and adapt to changing conditions.This ongoing refinement ensures the model stays aligned with business goals and user expectations over time, allowing for continuous improvement based on real-world feedback.
Here’s how it works:
This setup creates a continuous learning loop where the model self-corrects based on real-world usage, ensuring it stays aligned with domain-specific behavior.
In this example, with a banking gen AI chatbot, the application is evaluated to ensure the chatbot only responds to banking-related queries. If it answers irrelevant questions, an automated feedback loop using ORPO kicks in to fine-tune and redeploy the model.
(ORPO (Odds Ratio Preference Optimization) integrates supervised fine-tuning (SFT) and preference alignment by leveraging a simple log odds ratio term to create a penalty for disfavored responses and a strong adaptation signal for the chosen response. This approach is computationally efficient and doesn’t require a separate reference model or reward model, making it a simpler and more powerful alternative to methods like DPO or RLHF.)

Fine-tuning can help adapt a model to a required use case, before application deployment. This allows for more accurate, relevant and context-aware responses tailored to the specific needs of the target domain or user group.
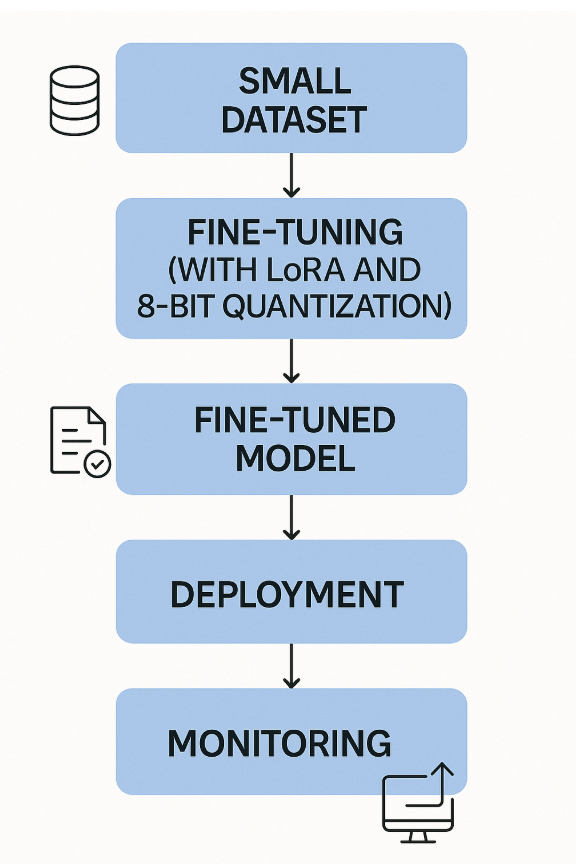
Here’s how it works:
This is ideal for quick iterations, experimentation with model behavior (e.g., tone or persona), or domain adaptation without full-scale retraining.
In this example, the model’s outputs are transformed to emulate a specific tone of voice (in this example – pirate speak). The pre-trained LLM (LLaMA 2 7B) is fine-tuned using a customized dataset (Databricks Dolly-15k).
More Resources:
