Introducing MLRun v1.10: Build better agents, monitor everything
We’re proud to announce a series of advancements in mlrun v1.10 designed to power your end-to-end orchestration layer for agentic AI applications.


At MLRun, we’re proud to announce a series of advancements in MLRun v1.10 designed to power your end-to-end orchestration layer for agentic AI applications. From a powerful and versitile prompt engineering upgrade, support for remote models and a brand new interface to monitor agent performance, MLRun is continuously evolving to meet the demands of cutting-edge AI applications.
Prompt engineering is at the heart of agentic AI, but it’s often messy and hard to scale. That’s why we’re introducing the LLM Prompt Artifact: a new way to turn each LLM + prompt + configuration into a reusable, version-controlled and production-ready building block.
For teams building complex gen AI pipelines, where each task might use a different prompt or model, this feature gives you the flexibility to experiment and optimize at every step, while keeping your workflows clean and production-ready.
With LLM Prompt Artifacts, you can:
The LLM Prompt Artifact turns prompt engineering into a structured, repeatable process, making it easier to build, test, and deploy agents that work.

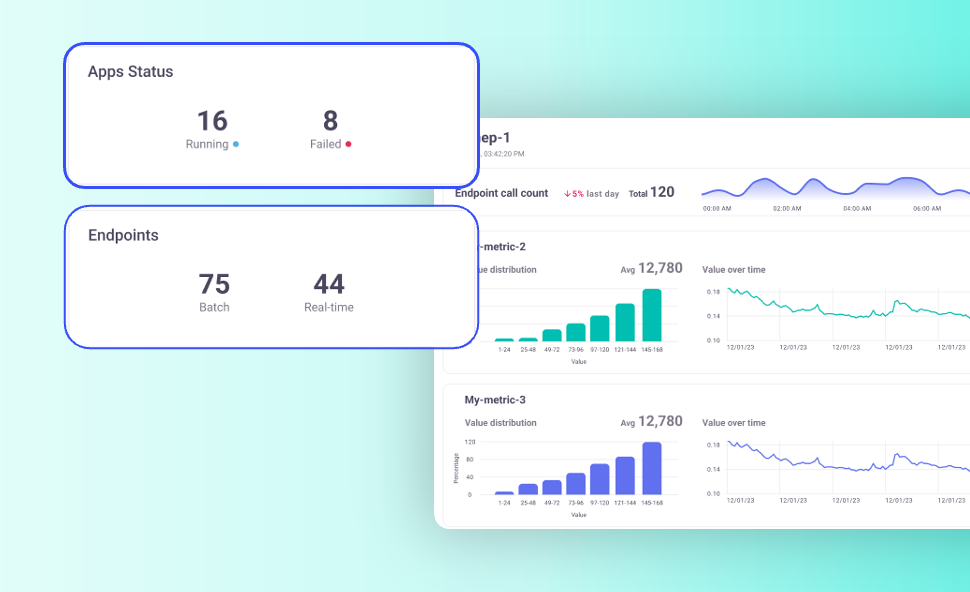
While monitoring deterministic AI systems is fairly straightforward, monitoring gen AI systems is new and complex territory. The AI monitoring ecosystem doesn’t offer a one size fits all solution, and many use cases call for a mix of different tools that can account for guardrails, hallucinations, compliance, security risks and performace degradation over time. One of MLRun’s main strengths is its open architecture, which lets you integrate with any third-party service. With MLRun you can integrate a custom monitoring set up that goes well beyond standard built-in dashboards.
As part of our ongoing work on the future of monitoring for gen AI, MLRun v1.10 introduces the Monitoring Applications view: a single, centralized dashboard that consolidates all your monitoring apps into one place. Instead of jumping between tools or manually checking individual apps, you now have a unified view of their status, activity, and results.
With this new UI, you can:
This dashboard gives you the tools to monitor and refine every part of the process, from prompt engineering to model evaluation. Now you can confidently deploy and scale agentic AI systems with the data to continuously improve them.
Agentic AI often requires combining the best tools and models from multiple sources, whether they’re stored locally or hosted on platforms like Hugging Face. But managing these external models can quickly become a headache, with duplicated files, scattered tracking, and unnecessary storage costs. Now, you can register and manage these remote models directly in MLRun without duplicating files or uploading them to your datastore.
With this feature, you can:
Need to run batch inference, scheduled evaluations, or one-time scoring tasks? With MLRun v1.10, you can now deploy serving graphs as Kubernetes jobs. This makes it easy to evaluate multiple prompts, compare agents in parallel, or run bulk tasks without spinning up unnecessary infrastructure.
MLRun v1.10 is more than just a version update, it’s a toolkit for building smarter, faster, and more reliable agentic AI applications. Beyond these features, this release is full of numerous bug fixes, documentation improvements and user requests. We want to extend a huge thank you to the MLRun community for your contributions and feedback.
Stay tuned for the next round of improvements. Ready to get started with MLR v1.10? Check out the release notes for more details, or dive into the docs to start exploring the new features.
We can’t wait to see what you build with MLRun v1.10. As always, we’re here to support you every step of the way.
Happy building!
The MLRun Team
