LLM as a Judge: Practical Example with Open-Source MLRun


LLMs can be used for evaluating other models, which is a method known as “LLM as a Judge”. This approach leverages the unique capabilities of LLMs to assess and monitor the performance and accuracy of models. In this blog, we will show a practical example of operationalizing and de-risking an LLM as a Judge in with the open-source MLRun platform.
“LLM as a judge” refers to using LLMs to evaluate the performance and output of AI models. The LLM can analyze the results based on predefined metrics such as accuracy, relevance, or efficiency. It may also be used to compare the quality of generated content, analyze how models handle specific tasks, or provide insights into strengths and weaknesses.
LLM as a Judge is an evaluation approach that helps bring applications to production and derives value from them much faster. This is because LLM as a Judge allows for:
When using a Large Language Model (LLM) as a judge for evaluating other models, several significant risks must be carefully considered to avoid faulty conclusions:
Addressing these risks requires thorough validation, human oversight, careful design of evaluation criteria and evaluating the model Judge for the task. This will ensure reliable and fair outcomes when using an LLM as an evaluator.
In this example, we’ll show how to implement LLM as a Judge as part of your monitoring system with MLRun. You can view the full steps with code examples here.
Here’s how it works:
To prompt engineer the judge you can follow the best practices here:
LLM as a Judge is a useful method that can scale model evaluation. With MLRun, you can quickly fine-tune and deploy the LLM that will be used as a Judge, so you can operationalize and de-risk your gen AI applications. Follow this demo to see how.
Just getting started with gen AI? Start with MLRun now.

LLM monitoring helps optimize for accuracy and efficiency, detect bias and ensure security and privacy. But common metrics like BLEU and ROUGE aren’t always accurate enough for LLM monitoring. By developing your own monitoring application, you can customize and tailor the metrics you need, monitor in real-time, integrate with other systems, and more. In this blog post, we explain how to do this with MLRun.
Monitoring generative AI applications and LLMs is an essential step in the AI pipeline. By monitoring, data professionals ensure models are accurate and bring business value. It also helps remove the risks associated with gen AI.
Overall, LLM monitoring can help:
There are many trackable LLM metrics, which can help meet the objectives detailed above. These include first-level metrics, model-related metrics, data metrics and more.
If the pipeline is: X -> Model -> Y
Given this, the common metrics include:
Additional metrics that can be monitored include:
In addition to these, data engineers and scientists can also come up with their own metrics, based on use cases and requirements. This is valuable for monitoring LLMs, since these popular metrics don’t always cover unique LLM monitoring needs.
For example:
By developing your own monitoring application, you can monitor LLMs based on the metrics you need, to ensure your LLM is fully-optimized to your use case. This will ensure it brings business value and help avoid LLM risks that have technological and business implications.
By developing and deploying your own monitoring application you can:
Open-source MLRun provides a radically simplified solution, allowing anyone to develop and deploy their own monitoring application in a few simple lines of code. Inherit the `MonitoringApplication` class, implement one method and that’s it!
You can see the full tutorial with code snippets and examples in the MLRun documentation.

MLRun is an open-source MLOps and gen AI orchestration framework designed to manage and automate the machine learning lifecycle. This includes everything from data ingestion and preprocessing to model training, deployment and monitoring, as well as de-risking. MLRun provides a unified framework for data scientists and developers to transform their ML code into scalable, production-ready applications.
In this blog post, we’ll show you how to get started with MLRun: creating a dataset, training the model, serving and deploying. You can also follow along by watching the video this blog post is based on or through the docs.
When starting your first MLRun project, don’t forget to star us on GitHub.
Now let’s get started.
An MLRun project helps organize and manage the various components and stages of an ML or gen AI workflow in an automated and streamlined manner. It integrates components like datasets, code, models and configurations into a single container. By doing so, it supports collaboration, ensures version control, enhances reproducibility and allows for logging and monitoring.
This will create the project object, which will be used to add and execute functions.
%%writefile data-prep.py
import pandas as pd
from sklearn.datasets import load_breast_cancer
def breast_cancer_generator():
“””
A function which generates the breast cancer dataset
“””
breast_cancer = load_breast_cancer()
breast_cancer_dataset = pd.DataFrame(
data=breast_cancer.data, columns=breast_cancer.feature_names
)
breast_cancer_labels = pd.DataFrame(data=breast_cancer.target, columns=[“label”])
breast_cancer_dataset = pd.concat(
[breast_cancer_dataset, breast_cancer_labels], axis=1
)
return breast_cancer_dataset, “label”
This is regular Python. MLRun will automatically log the returning data set and a label column name. 4. Create an MLRun function using project.set_function, together with the name of the Python file and parameters specifying requirements. These could include running the function as a job with a certain Docker image.
data_gen_fn = project.set_function(
“data-prep.py”,
name=”data-prep”,
kind=”job”,
image=”mlrun/mlrun”,
handler=”breast_cancer_generator”,
)
project.save() # save the project with the latest config
gen_data_run = project.run_function(
“data-prep”,
local=True,
returns=[“dataset”, “label_column”],
)
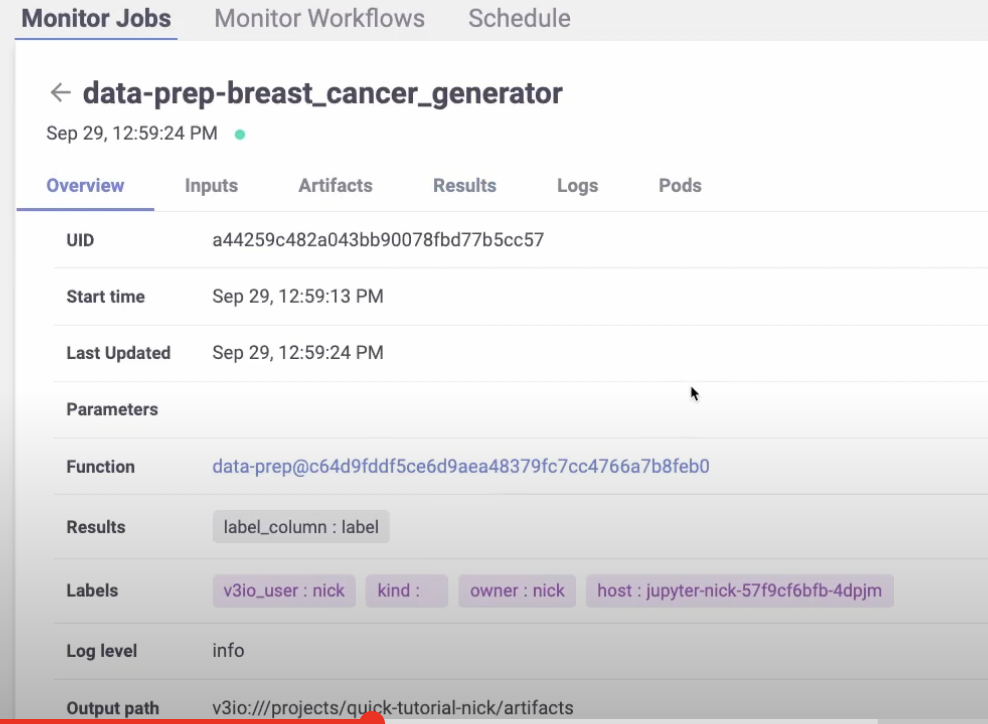
Now let’s see how to train a model using the dataset that we just created. Instead of creating a brand new MLRun function, we can import one from the MLRun function hub.
Here’s what it looks like:
You will find a number of useful and powerful functions out-of-the-box. We’ll use the Auto trainer function.
# Import the function
trainer = mlrun.import_function(“hub://auto_trainer”)
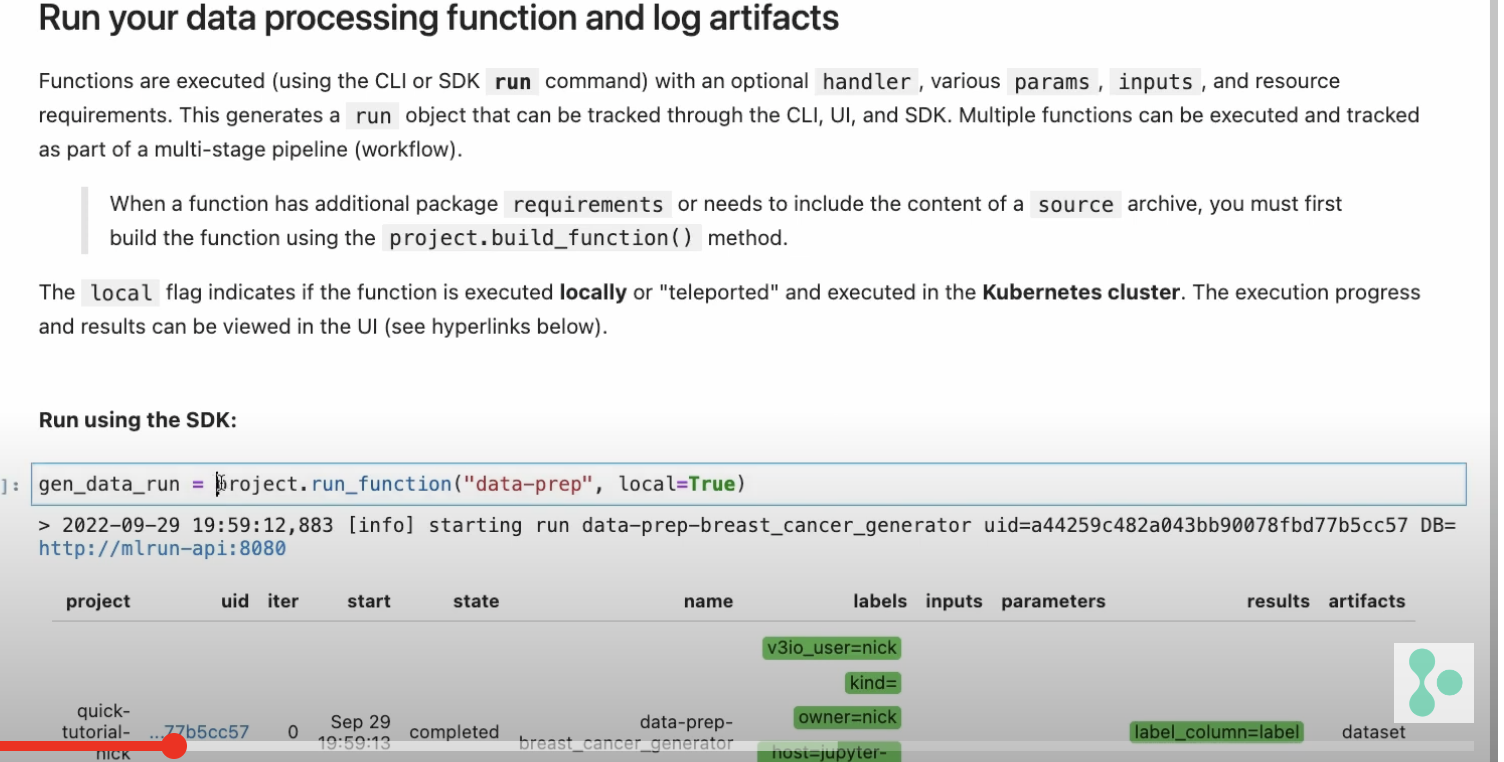
In this case, one of the parameters is the data set from our previous run.
trainer_run = project.run_function(
trainer,
inputs={“dataset”: data_prep_run.outputs[“dataset”]},
params={
“model_class”: “sklearn.ensemble.RandomForestClassifier”,
“train_test_split_size”: 0.2,
“label_columns”: data_prep_run.results[“label_column”],
“model_name”: “breast_cancer_classifier”,
},
handler=”train”,
)
The default is local=false, which means it will run behind the scenes on Kubernetes.
You will be able to see the pod and the print out statements.
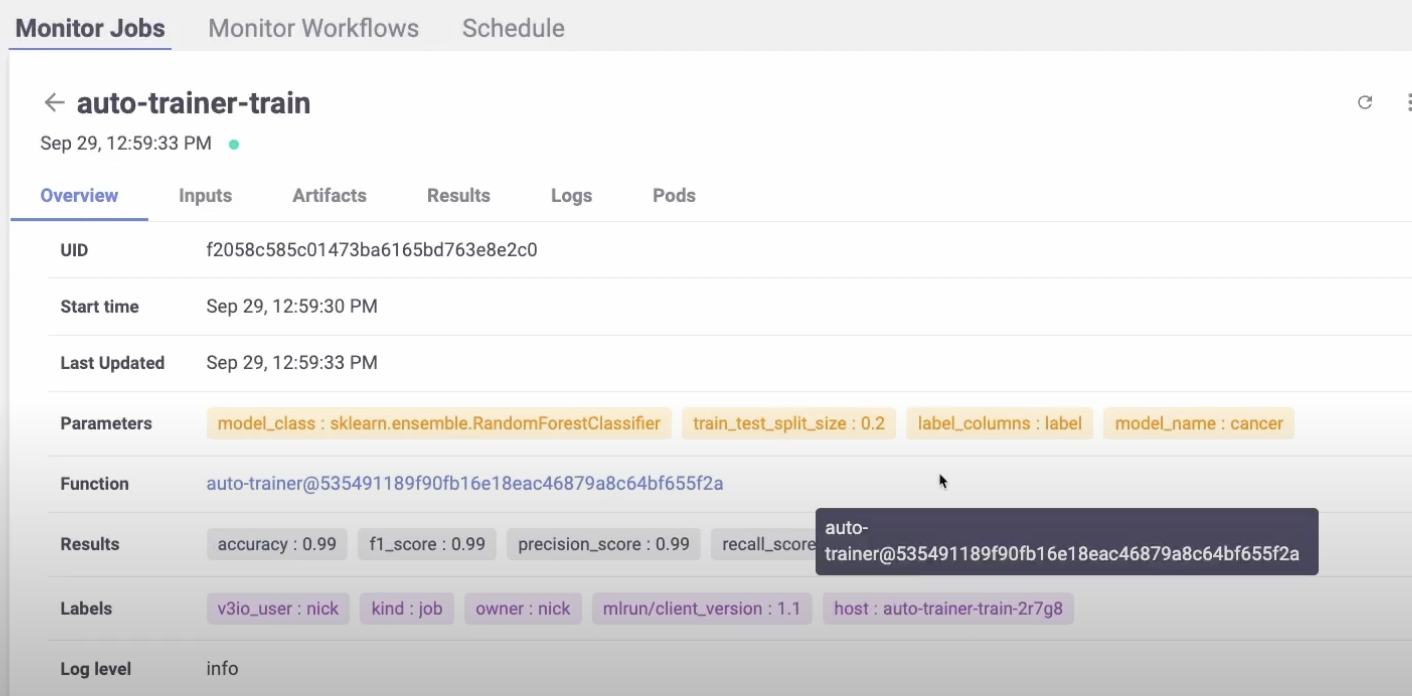
Now we can serve the trained model.
serving_fn = mlrun.new_function(
“breast_cancer_classsifier_servingserving”,
image=”mlrun/mlrun”,
kind=”serving”,
requirements=[“scikit-learn~=1.3.0”],
)
serving_fn.add_model(
“breast_cancer_classifier_endpoint”,
class_name=”mlrun.frameworks.SKLearnModelServer”,
model_path=trainer_run.outputs[“model”],,
)
In this example, we are using sklearn. But you can choose your preferred framework from this list:
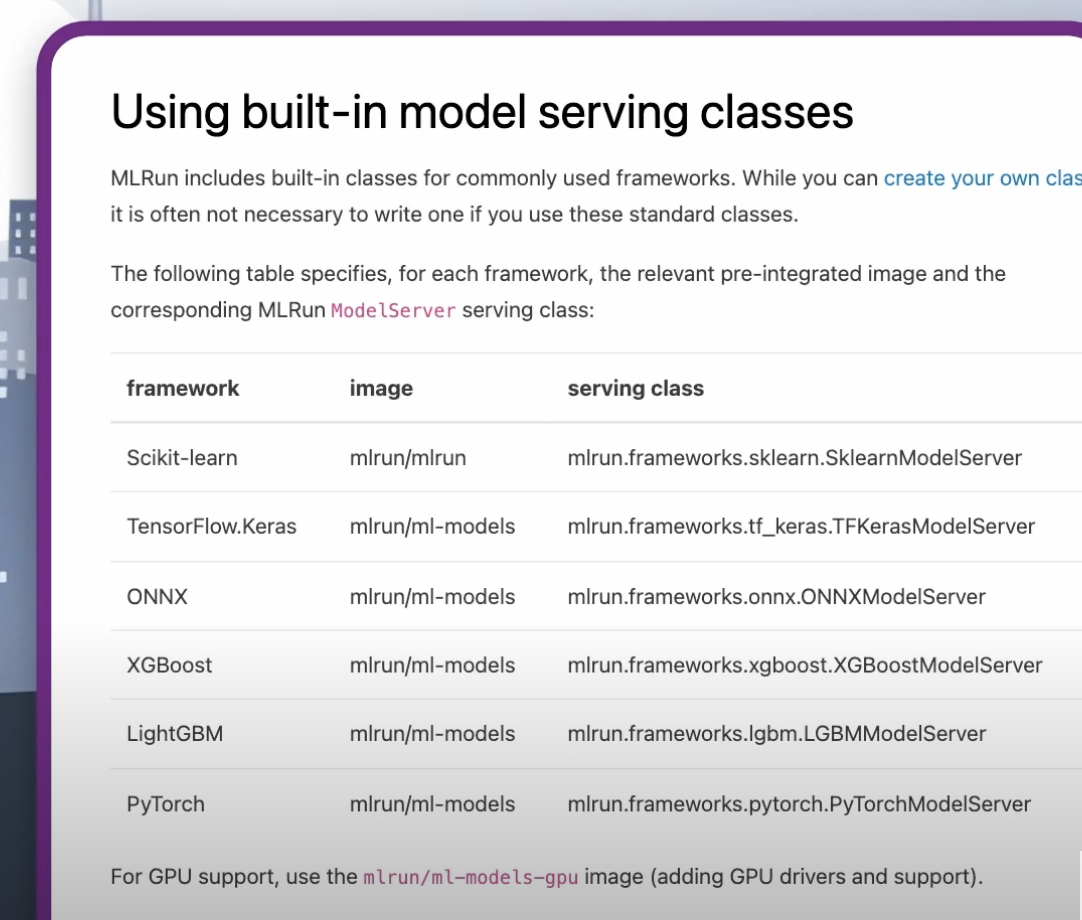
Or customize your own. You can read more about this in the docs.
The example below shows a simple, singular model. There are also more advanced models that include steps for data enrichment, pre-processing, post-processing, data transformations, aggregations and more.
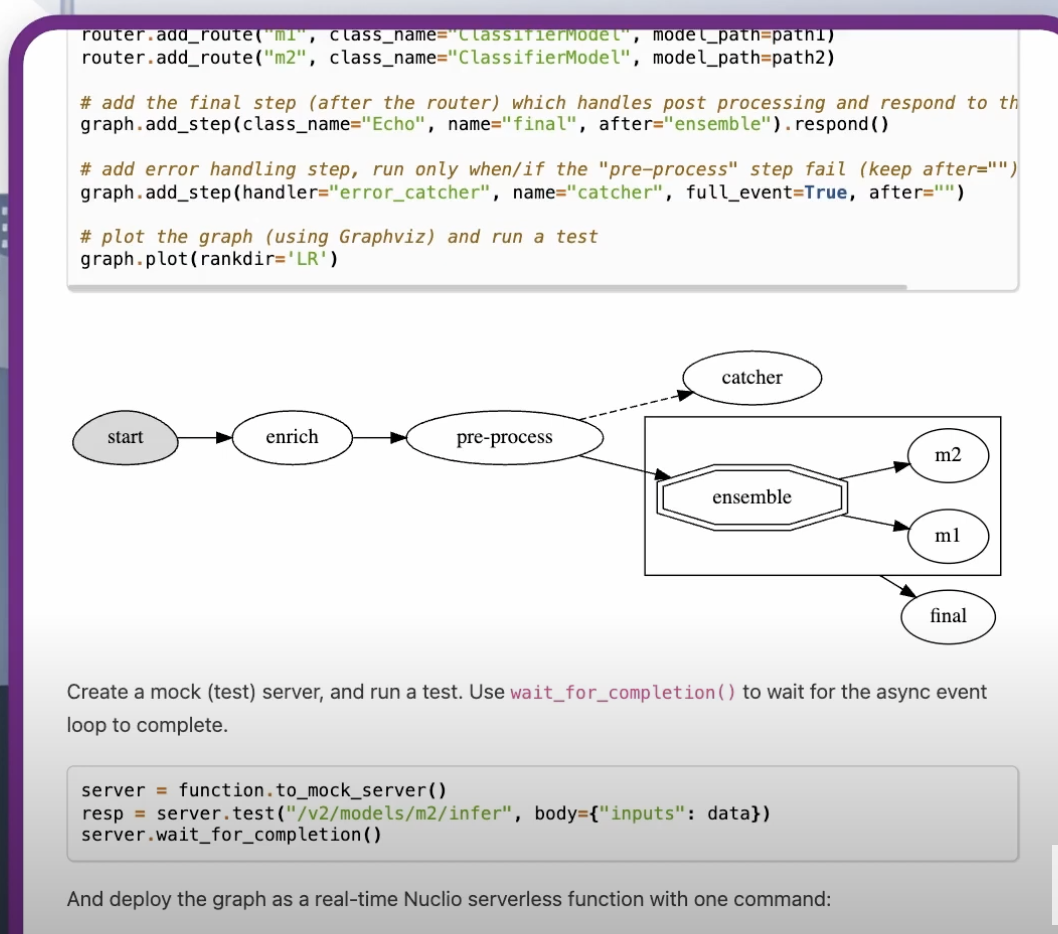
Read more about real-time serving here.
# Create a mock (simulator of the real-time function)
server = serving_fn.to_mock_server()
Use the mock server `test` method (server.test) to test the model server.
The last part of the code is the model server, which you can send data inputs to and acts exactly like a model server.
Finally, it’s time to deploy to production with a single line of code.
serving_fn.deploy()
This will take the code, all the parameters, the pre- and post-processing, etc., package them up in a container deployed on Kubernetes and expose them to an endpoint. The endpoint contains your transformation, pre- and post-processing, business logic, etc. This is all deployed at once, while supporting rolling upgrades, scale, etc.
That’s it! You now know how to use MLRun to manage and deploy ML models. As you can see, MLRun is more than just training and deploying models to an endpoint. It is an open source machine learning platform that helps build a production-ready application that includes everything from data transformations to your business logic to the model deployments to a lot more.

Developing a gen AI app requires multiple engineering resources, but with MLRun the process can be simplified and automated. In this blog post, we show a tutorial of building an application for a smart call center application. This includes a pipeline for generating data for calls and another pipeline for call analysis. For those of you interested in the business aspect, we added information in the beginning about how AI is impacting industries.
You can follow the tutorial along with the respective Notebook and clone the Git. Don’t forget to star us on Github when you do! You can also watch the tutorial video.
AI is changing our economy and ways of work. According to McKinsey, AI’s most substantial impact is in three main areas:
Redistributing profit pools – AIaaS (AI-as-a-Service) is added to the value chain, resulting in new solutions and entire value chains being replaced.
When building a gen AI app and operationalizing LLMs, it’s important to perform the following actions:
Now let’s dive into the hands-on tutorial.
The following tutorial shows how to build an LLM call center analysis application. We’ll show how you can use gen AI to analyze customer and agent calls so your audio files can be used to extract insights.
This will be done with MLRun in a single workflow. MLRun will:
As a reminder, you can:
This comprises six steps, some of which are based on MLRun’s Function Hub:
The resulting workflow will look like this:
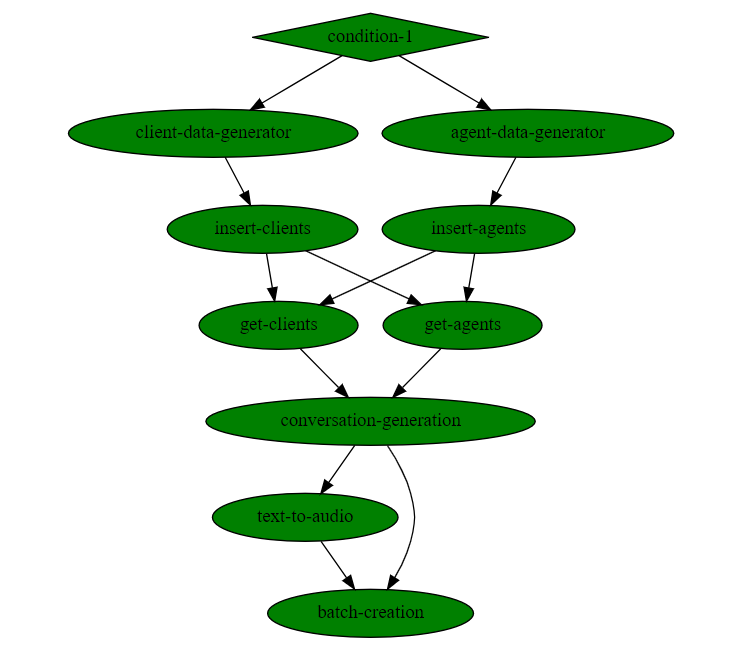
As you can see, no code is required. More details on each step and when to use them, in the documentation.
And it looks like this:
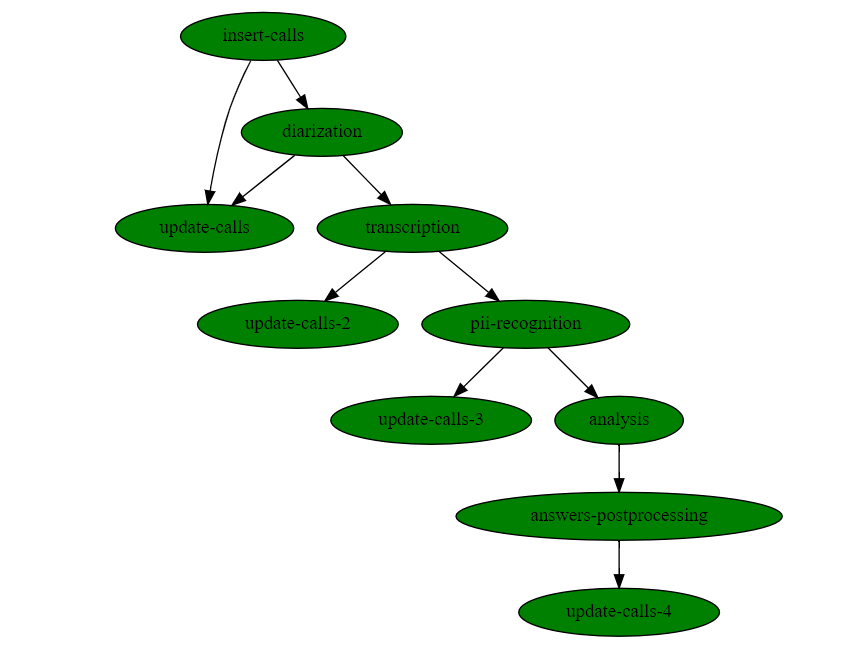
Similarly, no coding is required here either.
Here’s how some of the steps are executed:
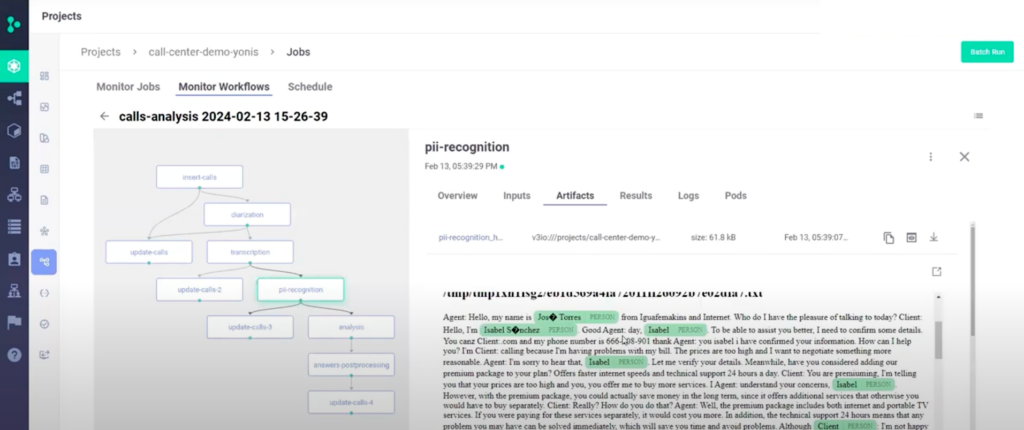

6. You can also use your database and the calls for developing new applications, like prompting your LLM to find a specific call in your call database in a RAG based chat app.To hear what a real call sounds like, watch the video of this tutorial.
In addition to simplifying the building and running of the pipelines, MLRun also allows auto logging, auto distribution and auto scaling resources.
