Fine-Tuning in MLRun: How to Get Started
How to fine tune an existing LLM quickly and easily with MLRun, with two practical hands-on examples.


Fine-tuning is the practice of training a pre-existing AI model on new, focused data. By enhancing the model’s domain-specific performance, organizations can make their LLMs production-ready and turn their generative AI applications into a competitive differentiator. In this blog, we’ll explore how MLRun simplifies and accelerates fine-tuning workflows with two practical, hands-on examples, which you can easily follow and replicate.
Fine-tuning is a machine learning method where a pre-trained model is further trained on a specialized dataset to adapt it to specific tasks or domains. Fine-tuning involves modifying the model’s internal parameters based on new data (rather than the model’s output), to enhance its performance for particular applications. This makes the model more specialized for specific tasks and valuable for business use cases.
Fine-tuning is considered a resource-efficient method because it leverages pre-trained models, rather than having to train a new model from scratch. However, resources for the fine-tuning process itself need to be managed efficiently to ensure cost-effectiveness.
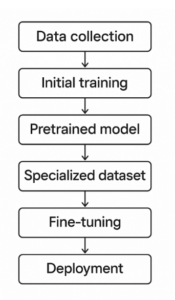
In AI pipelines, fine-tuning takes place in the development pipelines, after data is collected and initial models are trained. Before deploying the model, it’s recommended to evaluate the fine-tuned model and ensure it meets required standards.
MLRun provides pre-made functions that will tune, track the model/dataset, dynamically allocate GPUs in a K8s cluster, etc. Then, MLRun can be used to serve the newly fine tuned model at an endpoint. MLRun can then be used to monitor the model over time with custom metrics/guardrails (see example #1 below).
You can find these functions in these resources. Below we show examples of how to fine-tune with MLRun. There are also more demos and resources in the end:
Let’s take a look at two examples of how to fine-tune with MLRun. Follow along with the tutorials on your own:
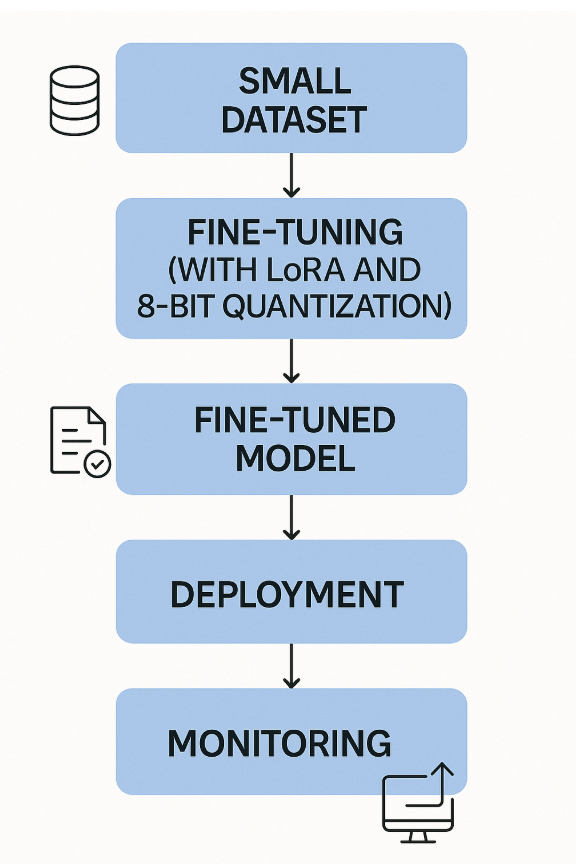
Fine-tuning can take place after an application is developed and in the monitoring phase. By observing how the model performs in production, such as how it handles edge cases, evolving user behavior, or domain-specific nuance, teams can fine-tune the model to correct drift, improve accuracy and adapt to changing conditions.This ongoing refinement ensures the model stays aligned with business goals and user expectations over time, allowing for continuous improvement based on real-world feedback.
Here’s how it works:
This setup creates a continuous learning loop where the model self-corrects based on real-world usage, ensuring it stays aligned with domain-specific behavior.
In this example, with a banking gen AI chatbot, the application is evaluated to ensure the chatbot only responds to banking-related queries. If it answers irrelevant questions, an automated feedback loop using ORPO kicks in to fine-tune and redeploy the model.
(ORPO (Odds Ratio Preference Optimization) integrates supervised fine-tuning (SFT) and preference alignment by leveraging a simple log odds ratio term to create a penalty for disfavored responses and a strong adaptation signal for the chosen response. This approach is computationally efficient and doesn’t require a separate reference model or reward model, making it a simpler and more powerful alternative to methods like DPO or RLHF.)

Fine-tuning can help adapt a model to a required use case, before application deployment. This allows for more accurate, relevant and context-aware responses tailored to the specific needs of the target domain or user group.
Here’s how it works:
This is ideal for quick iterations, experimentation with model behavior (e.g., tone or persona), or domain adaptation without full-scale retraining.
In this example, the model’s outputs are transformed to emulate a specific tone of voice (in this example – pirate speak). The pre-trained LLM (LLaMA 2 7B) is fine-tuned using a customized dataset (Databricks Dolly-15k).
More Resources:

Today we’re announcing MLRun 1.8, now available to the community. This latest version adds to the series of improvements to LLM monitoring released in 1.7, with in-platform alerts. Plus, several more improvements to help to track and evaluate models, and navigate the platform with ease.
Read all the details below:
MLRun v1.7 introduced a flexible monitoring infrastructure, the ability to monitor unstructured data, metrics customization, and more.
MLRun v1.8 builds on these capabilities and now includes monitoring alerts built into the MLRun UI.
Users can set up alerts on criteria such as:
Once alerted, users can click through to the flagged issues and investigate directly in MLRun, without having to context switch to external monitoring systems.
Experiment tracking is used to measure metrics, compare results, reproduce experiments and optimize models. This is a core MLRun capability.
Now, MLRun v1.8 supports experiment tracking for document-based models, like LLMs. This is enabled through the LangChain API, which is integrated into vector databases.
Users can track their documents as artifacts, with metadata like:
Debugging LLMs is a complicated process. It requires: 1) Deployment 2) Realizing there’s an issue 3) Identifying the root cause 4) Analysis and evaluation 5) Fixing 6) Redeploying. This process is long, technologically complex and resource-intensive. It’s also prone to potential errors.
In MLRun v.1.8, this process is shorter and more resource-efficient. Users can now monitor and evaluate models before deploying them. MLRun runs the model, returning performance results without consuming unnecessary compute resources.
Managing large-scale projects across teams requires a reliable and user-friendly system.
Following user requests, MLRun v1.8 includes pagination, to enhance responsiveness and reduce scrolling and performance bottlenecks arising from long page loading times.
What’s your feedback on MLRun 1.8? Join the community and share your insights and requirements for future releases.
Explore MLRun 1.8.

MLRun is an open-source framework that orchestrates the entire generative AI lifecycle, from development to deployment in Kubernetes. In this article, we’ll show how MLRun replaces manual deployment processes, allowing you to get from your notebook to production in just a few lines of code.
As a data professional, you’re probably familiar with the following process:
The traditional process described above is fraught with challenges:
MLRun addresses these challenges by allowing you to easily run your local code in K8s production environments as a batch job or a remote real-time deployment. MLRun eliminates the need to worry about the complexity of Kubernetes, abstracting and streamlining the process. MLRun also supports scaling and configuring resources, such as GPU, Memory, CPU, etc. It provides a simple way to scale resources, without requiring users to understand the inner workings of Kubernetes.
What’s left is simply to monitor the functionality and behavior of your AI system once it’s live, which can also take place in MLRun.
Here’s how MLRun achieves this:
Here’s what the same process looks like, but with MLRun:
| Before MLRun | After MLRun |
| You want to run a batch fine-tuning job for your LLM, but your code requires a lot of memory, CPU, GPUs. It also needs a number of Python requirements packages to run and fine-tune the LLM. | By using MLRun this flow is very simple. You only need to connect your local IDE to MLRun, create a project, create an MLRun function set and run your code using the relevant resources. With this flow, you can develop and run your code in a Kubernetes from the beginning of the development phase with only a few code lines. |
| You must run your code on your K8s cluster because your local computer doesn’t have enough resources. For this, you need to create a K8s resource and maybe a new Docker image with the new Python requirements. | To run your code in a Kubernetes cluster, create an MLRun function that runs your Python code. Then, add the amount of resources (memory, CPU and GPU), and add Python requirements. MLRun will use those values and run your fine-tuning job in Kubernetes and manage the deployment. |
| Once you’ve successfully run the function on the K8s cluster, you need to version and track your experiment results (LLM and the fine-tune job results). This is essential to understand where and why you need to improve your fine-tune job. | Now that you have a model that has been fine-tuned by the MLRun function, you can track the model artifact as part of the MLRun model artifactory, with the model version, labels or the model metrics. |
| In some projects, the model inference is done in a batch, in others it’s in real-time. If this is a real-time deployment, you need to create a K8s resource that serves the model with the user prompts or create a batch job that does the same. Both should run in the K8s cluster for production testing, and you need to manage those resources by yourself. | In some projects, the model inference is done in a batch, in others it’s in real-time. In MLRun, you can do both. You can serve your LLM in real-time or collect the prompts and run the same in batch for the LLM evaluations, in just a couple of lines of code. |
| Once you serve the model, you need to monitor and test how your model is behaving and if the model outputs meet your criteria for deployment in production, using accuracy, performance or other custom metrics. | Once you serve the model, monitor your LLM outputs and inputs and check the model performance and usage by enabling MLRun model monitoring. This is an essential part of the model development, helping you better understand if you need to retrain the model or the model outputs so they meet your criteria for deployment in production. |
| Once your project is ready to deploy in production systems you need to run some of the steps above in the production cluster again | Once your project is ready for production, you can easily move your project from dev system and move the same project configuration to production system, by using MLRun CI/CD automation. |
MLRun can take your code and run and manage your functions and artifacts in Kubernetes environments from your first deployment. This allows you to focus on development and decreases the time needed to deploy AI projects in production, while maintaining a production-first mindset approach.
1. On your laptop, install MLRun and configure your remote environment. Now you have your MLRun environment ready to develop your project from your laptop to production.
2. Create your MLRun project by using the MLRun SDK.
3. Run your Python code as an MLRun function. For a remote or batch function you can run your code locally or on your k8s cluster from the beginning of the development phase (always keep production mindset approach). You can also log models and different artifact types to your system experiment tracking management.
4. Based on the run and the experiment tracking you can monitor your result and make the way to production more easy and convenient.
More Resources:
MLRun simplifies and automates the various stages of the AI lifecycle. Here are some key use cases where you can use MLRun:

A generative AI copilot is an interactive gen AI assistant that is designed to amplify human capabilities while working together interactively. The term “gen AI co-pilot” is inspired by the aviation concept of a copilot, who assists the main pilot to ensure smooth and successful flying. You can develop your own copilot with open-source MLRun, which will orchestrate the AI pipelines at scale with pre-built components.
In this blog post, we’ll dive into the concept of a gen AI copilot and show a demo of building one with MLRun.
A copilot in generative AI is an AI-powered assistant designed to work interactively and collaboratively with humans in real-time to enhance our capabilities. This could include conducting tasks like automating repetitive assignments, generating drafts, retrieving information, transcription of conversations, analyzing data, providing insights, writing and testing code, or generating content. With a copilot, we can work faster, more effectively and at a larger scale.
Some of the most popular copilots in use today are:
A gen AI copilot leverages LLMs to understand user input, process it, and generate relevant outputs for tasks such as answering questions, creating content, or writing code. It combines specialized tools or APIs to tailor responses. With RAG, it can also fetch and incorporate real-time data, ensuring accuracy and relevance.
The system adapts through user feedback, integrates with external tools for automation, and maintains privacy and compliance standards to deliver secure, efficient, and personalized assistance across various domains.
Workflows are the sequences of tasks or actions that the copilot automates or assists with, based on user input and specific goals. They typically involve multi-step operations, integrations with external tools, and contextual understanding to ensure tasks are completed effectively.

A customer support copilot, for example, might include the following workflows:
5. Data Compliance and Logging – Ensuring all client interactions adhere to regulatory standards. For example, automatically logging the client interaction into the organization’s system while ensuring compliance with data protection and regulatory standards (e.g., GDPR, HIPAA), flagging any sensitive or non-compliant elements for review and maintaining a secure audit trail for accountability.
MLRun is an open-source AI orchestration framework that simplifies and accelerates the development and deployment of AI models. Building a copilot with MLRun allows for:
Customer service copilots can serve multiple use cases, from a 24/7 support call center to escalation management to global multilingual support. In the example below, you can see a demo of an MLRun copilot. It shows what such a copilot could look like in a private banking client relationship management scenario.
Meet Miss Chen, who recently invested in green energy bonds and is looking for advice on reinvesting additional funds. Together with the copilot, the banker identifies and recommends a relevant investment opportunity based on the client’s history. In addition, the co-pilot helps the agent anticipate future opportunities, like biotech investments, based on client interests, which expands the bank’s role in the client’s portfolio.
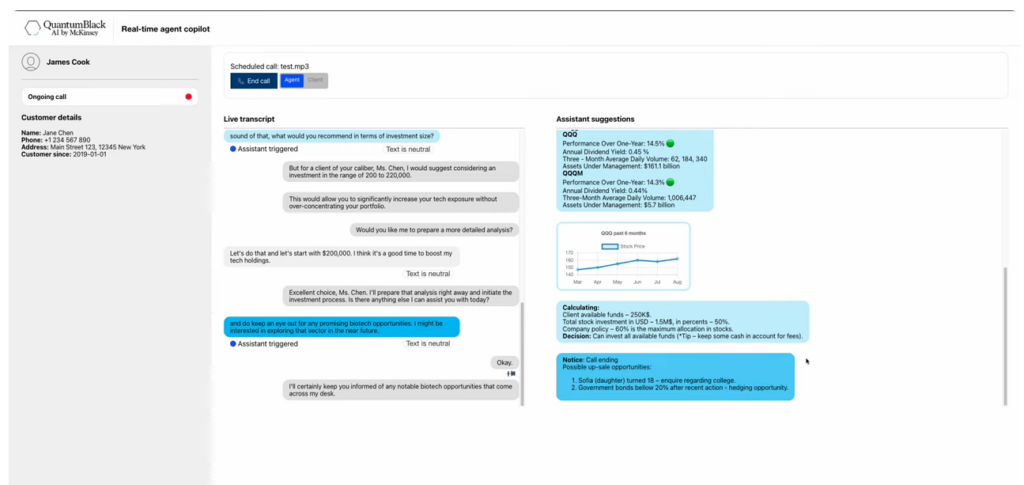
The banker also proactively shares research materials from reputable sources, retrieved by the copilot, to support informed decision-making. This fosters a sense of trust and expertise while generating more business for the bank.
The copilot emphasizes personalized service, strategic investment advice and proactive support for the client’s needs. It helps the human agent provide personal touches, such as acknowledging the client’s daughter’s achievements and offering tailored solutions, to build trust and loyalty. This long-term retention through proactive service ensures steady revenue from high-net-worth clients.
In the end, the co-pilot can create a hyper-personalized follow-up email based on the conversation for accountability and to close the deal.

As organizations transition from experimenting with LLMs to deploying gen AI applications and driving business value, data professionals face operationalization challenges. These include hallucinations, bias, model misuse, PII leakage, harmful content, inaccuracy, and more. Detecting and addressing these issues requires robust monitoring solutions in the AI pipeline.
By ensuring monitoring is part of AI pipeline orchestration, data professionals can implement a continuous feedback loop. The monitoring results can be used to fine-tune models, ensuring they are high-performing, reliable and accurate. This ensures risks are mitigated before reaching production, allowing for the integrity and operational stability of gen AI applications.
MLRun can integrate with any monitoring application, regardless of its ecosystem. This means users can use MLRun to orchestrate their gen AI application, including tasks like data preparation, model tuning, customization, validation and model optimization. Then, they can view monitoring results either in MLRun or their monitoring application of choice, and feed the results back to the AI pipeline.
Integrating MLRun with an external monitoring application is simple and straightforward. Here’s how it works:
Integrating with your monitoring application takes place through their SDK or API. Explore and identify your application’s SDK or find the API endpoints, request payloads and response structure in the documentation.
In MLRun, implement a Python class that inherits from MLRun’s ModelMonitoringApplication base class.
This class must include the do_tracking method, which defines the logic for interacting with the external application through the API or SDK.
The do_tracking method returns a list of key-value metrics and outcomes, including details like detected drift or model performance metrics. This abstraction ensures compatibility with any monitoring application.
After defining the Python class, register it as a monitoring function in MLRun. Use the set_model_monitoring_function method to add the function to your MLRun project and deploy it.
Once deployed, the monitoring application integrates seamlessly into the MLRun workflow.
You can see an example of how this works with open-source Evidently right here.
MLRun offers several key advantages for integrating external monitoring applications:
Model monitoring is foundational for maintaining reliable gen AI applications. MLRun simplifies the process by offering a generic, modular approach to integrating external monitoring applications. Whether your organization uses a market-leading tool or a custom-built solution, MLRun can fit seamlessly into your monitoring strategy.

As the open-source maintainers of MLRun, we’re proud to announce the release of MLRun v1.7. MLRun is an open-source AI orchestration tool that accelerates the deployment of gen AI applications, with features such as LLM monitoring, data management, guardrails and more. We provide ready-made scenarios that can be easily implemented by teams in organizations. This new release is packed with powerful features designed to make gen AI deployments more flexible and faster than ever before.
Specifically, V1.7 brings significant LLM monitoring enhancements, helping users ensure the integrity and operational stability of LLMs in production environments. Additional updates introduce performance optimizations, multi-project management, and more.
Read all the details below:
MLRun 1.7 introduces a new, flexible monitoring infrastructure that enables seamless integration of external tools and applications into AI pipelines, using APIs and pre-built integration points. This includes tools for external logging, alerting, metrics systems, etc.
For instance, users can now:
Given that LLMs primarily handle unstructured data, one of the key advances in MLRun 1.7 is its enhanced ability to enable tracking this kind of data with more precision.
A common way to monitor LLMs is to create another model that would act as a judge. See a demo of how this works.
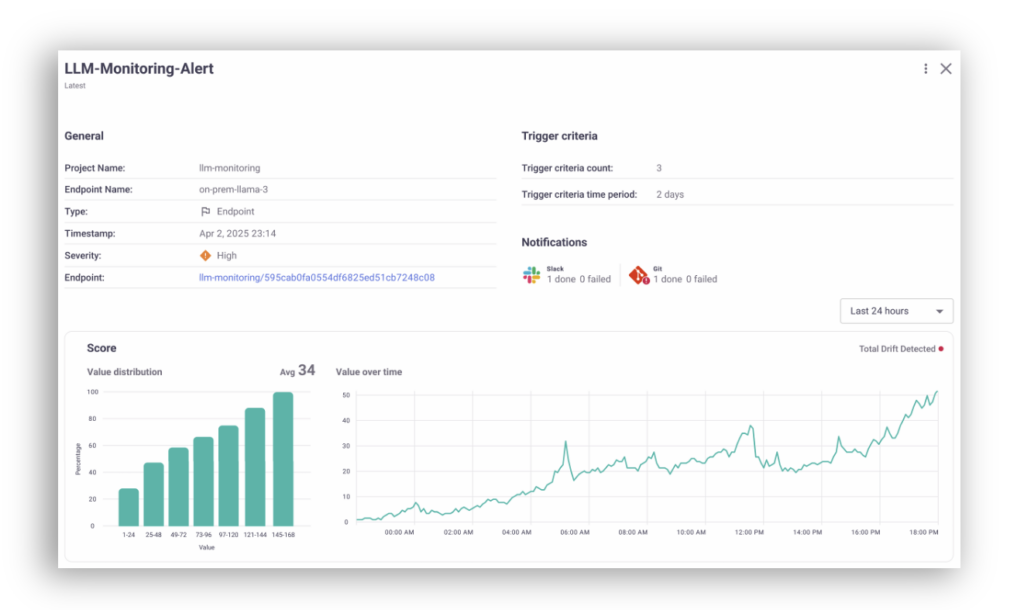
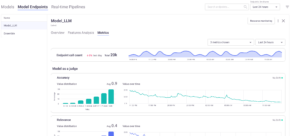
MLRun 1.7 introduces a new endpoint metrics UI. Its expanded endpoint monitoring capabilities allow users to:
For example, a time-series chart could indicate a bottleneck in the inference pipeline or model scaling issues.
The ability to track, visualize, and analyze endpoint performance enables teams to adjust operational parameters or retrain models as soon as performance starts to degrade. This reduces downtime or adverse effects in production environments.
With these capabilities, users can now customize their monitoring stacks per their business and tech stack requirements. Future releases will continue to enhance these capabilities, with more features and integrations for monitoring. This will allow for even greater flexibility and user control. So please share your feedback, so we can extend them based on your needs.
See a gen AI banking chatbot that uses MLRun’s new monitoring capabilities for fine-tuning, ensuring it only answers banking-related questions. This helps address the risks associated with gen AI, like hallucinations, inaccuracies, bias, harmful content, and more.
Version 1.7 simplifies the process of deploying Docker images, making it easier for users to run applications and models. Previously, deploying applications or models via Docker required manual configuration, with open-source Nuclio, and integration steps. Now, users can simply provide a Docker image and deploy it with minimal setup.
This improvement opens up development workflow possibilities. For example, users can more easily integrate custom UIs or dashboards that can interact with deployed models, allowing for more advanced and customized monitoring capabilities.
For enterprises working on multiple projects across diverse teams, keeping track of workflows and active jobs can become overwhelming. MLRun 1.7 introduces a cross-project view that consolidates all activities across projects into a single, centralized dashboard.
The cross-project view provides real-time visibility into all active jobs, workflows, and ML models across different projects. Users can:
This is especially valuable for organizations with complex environments where multiple teams may be working on different but interrelated projects.
Finally, MLRun 1.7 introduces improvements based on the invaluable feedback from you, our community users. We listened to the requirements and are releasing features that provide value in areas the community cares about most. This version introduces improved UI responsiveness, more efficient handling of large datasets, and a host of usability fixes. We look forward to your continued feedback on this version and the upcoming ones as well.
We’re looking forward to hearing your feedback about MLRun 1.7 and your future needs for the upcoming versions. Join the community and share your insights and requirements.

LLMs can be used for evaluating other models, which is a method known as “LLM as a Judge”. This approach leverages the unique capabilities of LLMs to assess and monitor the performance and accuracy of models. In this blog, we will show a practical example of operationalizing and de-risking an LLM as a Judge in with the open-source MLRun platform.
“LLM as a judge” refers to using LLMs to evaluate the performance and output of AI models. The LLM can analyze the results based on predefined metrics such as accuracy, relevance, or efficiency. It may also be used to compare the quality of generated content, analyze how models handle specific tasks, or provide insights into strengths and weaknesses.
LLM as a Judge is an evaluation approach that helps bring applications to production and derives value from them much faster. This is because LLM as a Judge allows for:
When using a Large Language Model (LLM) as a judge for evaluating other models, several significant risks must be carefully considered to avoid faulty conclusions:
Addressing these risks requires thorough validation, human oversight, careful design of evaluation criteria and evaluating the model Judge for the task. This will ensure reliable and fair outcomes when using an LLM as an evaluator.
In this example, we’ll show how to implement LLM as a Judge as part of your monitoring system with MLRun. You can view the full steps with code examples here.
Here’s how it works:
To prompt engineer the judge you can follow the best practices here:
LLM as a Judge is a useful method that can scale model evaluation. With MLRun, you can quickly fine-tune and deploy the LLM that will be used as a Judge, so you can operationalize and de-risk your gen AI applications. Follow this demo to see how.
Just getting started with gen AI? Start with MLRun now.

LLM monitoring helps optimize for accuracy and efficiency, detect bias and ensure security and privacy. But common metrics like BLEU and ROUGE aren’t always accurate enough for LLM monitoring. By developing your own monitoring application, you can customize and tailor the metrics you need, monitor in real-time, integrate with other systems, and more. In this blog post, we explain how to do this with MLRun.
Monitoring generative AI applications and LLMs is an essential step in the AI pipeline. By monitoring, data professionals ensure models are accurate and bring business value. It also helps remove the risks associated with gen AI.
Overall, LLM monitoring can help:
There are many trackable LLM metrics, which can help meet the objectives detailed above. These include first-level metrics, model-related metrics, data metrics and more.
If the pipeline is: X -> Model -> Y
Given this, the common metrics include:
Additional metrics that can be monitored include:
In addition to these, data engineers and scientists can also come up with their own metrics, based on use cases and requirements. This is valuable for monitoring LLMs, since these popular metrics don’t always cover unique LLM monitoring needs.
For example:
By developing your own monitoring application, you can monitor LLMs based on the metrics you need, to ensure your LLM is fully-optimized to your use case. This will ensure it brings business value and help avoid LLM risks that have technological and business implications.
By developing and deploying your own monitoring application you can:
Open-source MLRun provides a radically simplified solution, allowing anyone to develop and deploy their own monitoring application in a few simple lines of code. Inherit the `MonitoringApplication` class, implement one method and that’s it!
You can see the full tutorial with code snippets and examples in the MLRun documentation.


MLRun is an open-source MLOps and gen AI orchestration framework designed to manage and automate the machine learning lifecycle. This includes everything from data ingestion and preprocessing to model training, deployment and monitoring, as well as de-risking. MLRun provides a unified framework for data scientists and developers to transform their ML code into scalable, production-ready applications.
In this blog post, we’ll show you how to get started with MLRun: creating a dataset, training the model, serving and deploying. You can also follow along by watching the video this blog post is based on or through the docs.
When starting your first MLRun project, don’t forget to star us on GitHub.
Now let’s get started.
An MLRun project helps organize and manage the various components and stages of an ML or gen AI workflow in an automated and streamlined manner. It integrates components like datasets, code, models and configurations into a single container. By doing so, it supports collaboration, ensures version control, enhances reproducibility and allows for logging and monitoring.
This will create the project object, which will be used to add and execute functions.
%%writefile data-prep.py
import pandas as pd
from sklearn.datasets import load_breast_cancer
def breast_cancer_generator():
“””
A function which generates the breast cancer dataset
“””
breast_cancer = load_breast_cancer()
breast_cancer_dataset = pd.DataFrame(
data=breast_cancer.data, columns=breast_cancer.feature_names
)
breast_cancer_labels = pd.DataFrame(data=breast_cancer.target, columns=[“label”])
breast_cancer_dataset = pd.concat(
[breast_cancer_dataset, breast_cancer_labels], axis=1
)
return breast_cancer_dataset, “label”
This is regular Python. MLRun will automatically log the returning data set and a label column name. 4. Create an MLRun function using project.set_function, together with the name of the Python file and parameters specifying requirements. These could include running the function as a job with a certain Docker image.
data_gen_fn = project.set_function(
“data-prep.py”,
name=”data-prep”,
kind=”job”,
image=”mlrun/mlrun”,
handler=”breast_cancer_generator”,
)
project.save() # save the project with the latest config
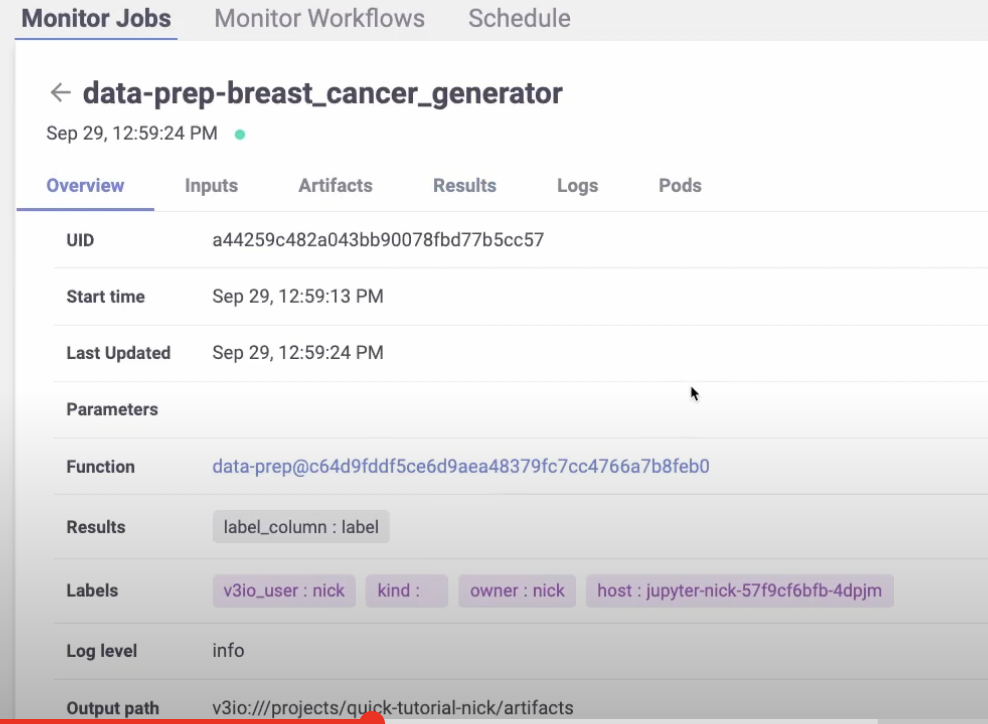
gen_data_run = project.run_function(
“data-prep”,
local=True,
returns=[“dataset”, “label_column”],
)
Now let’s see how to train a model using the dataset that we just created. Instead of creating a brand new MLRun function, we can import one from the MLRun function hub.
Here’s what it looks like:
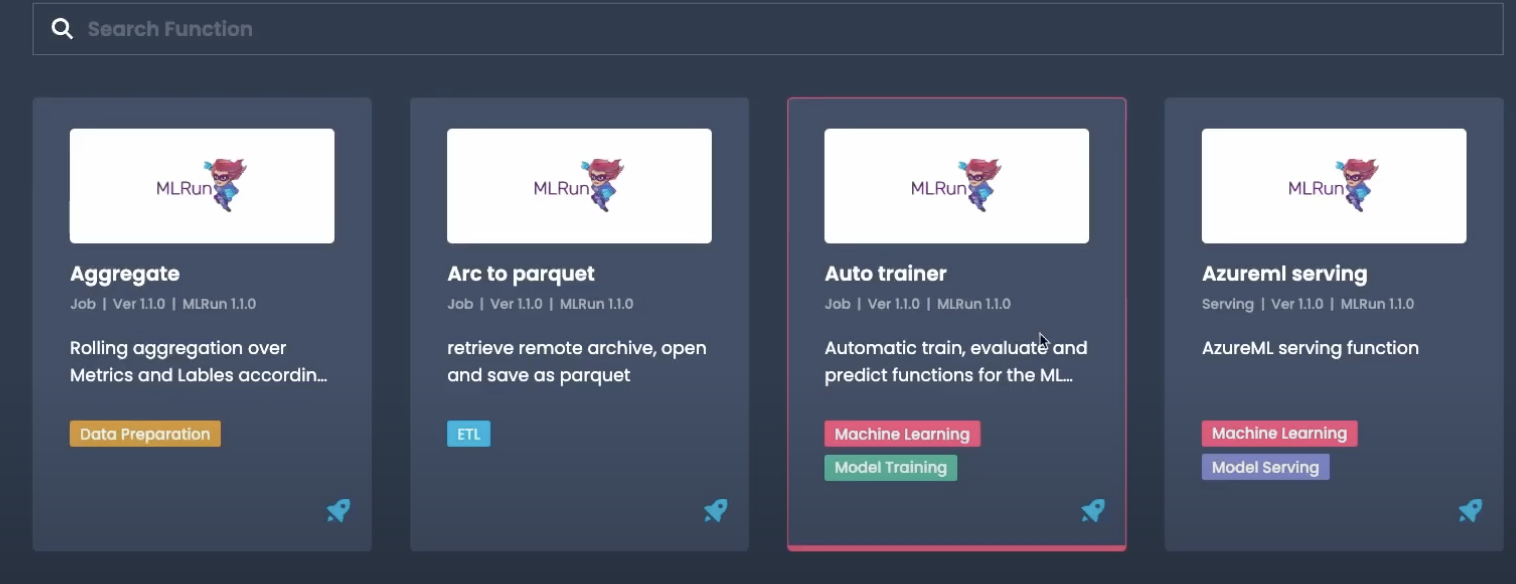
You will find a number of useful and powerful functions out-of-the-box. We’ll use the Auto trainer function.
# Import the function
trainer = mlrun.import_function(“hub://auto_trainer”)
In this case, one of the parameters is the data set from our previous run.
trainer_run = project.run_function(
trainer,
inputs={“dataset”: data_prep_run.outputs[“dataset”]},
params={
“model_class”: “sklearn.ensemble.RandomForestClassifier”,
“train_test_split_size”: 0.2,
“label_columns”: data_prep_run.results[“label_column”],
“model_name”: “breast_cancer_classifier”,
},
handler=”train”,
)
The default is local=false, which means it will run behind the scenes on Kubernetes.
You will be able to see the pod and the print out statements.
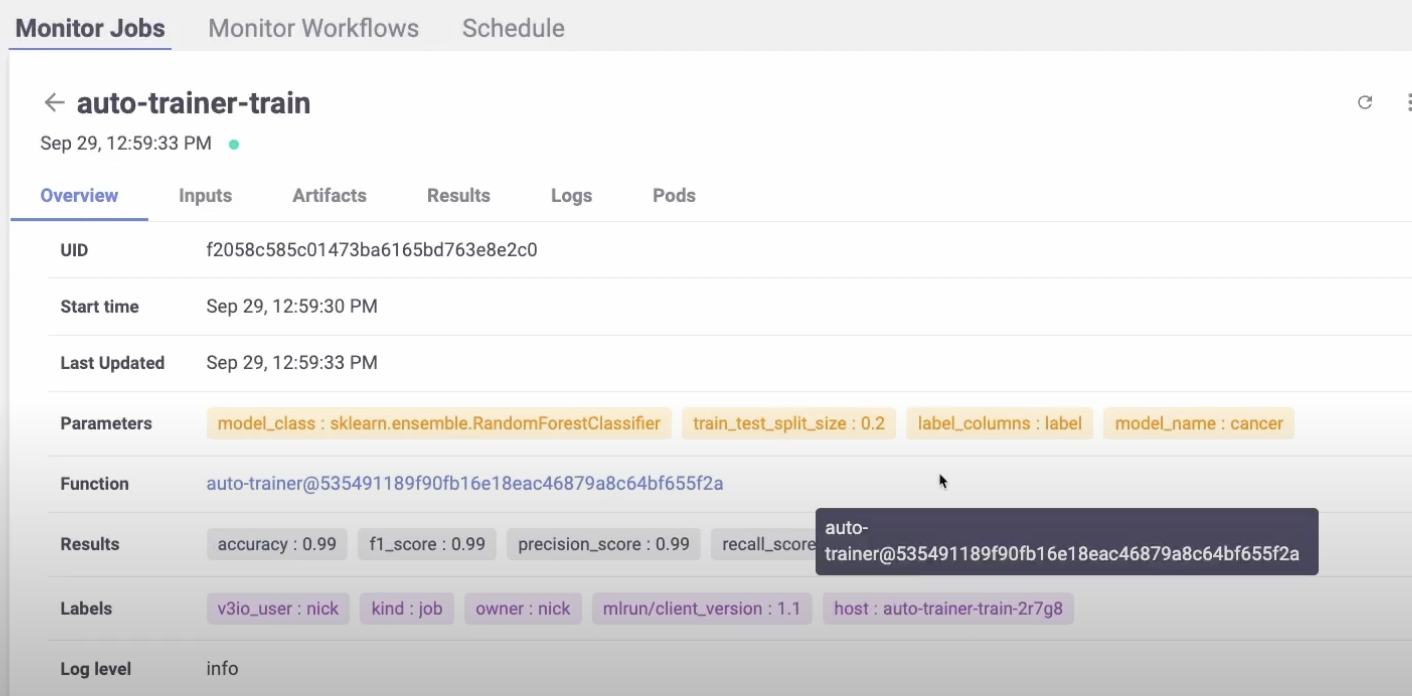
Now we can serve the trained model.
serving_fn = mlrun.new_function(
“breast_cancer_classsifier_servingserving”,
image=”mlrun/mlrun”,
kind=”serving”,
requirements=[“scikit-learn~=1.3.0”],
)
serving_fn.add_model(
“breast_cancer_classifier_endpoint”,
class_name=”mlrun.frameworks.SKLearnModelServer”,
model_path=trainer_run.outputs[“model”],,
)
In this example, we are using sklearn. But you can choose your preferred framework from this list:
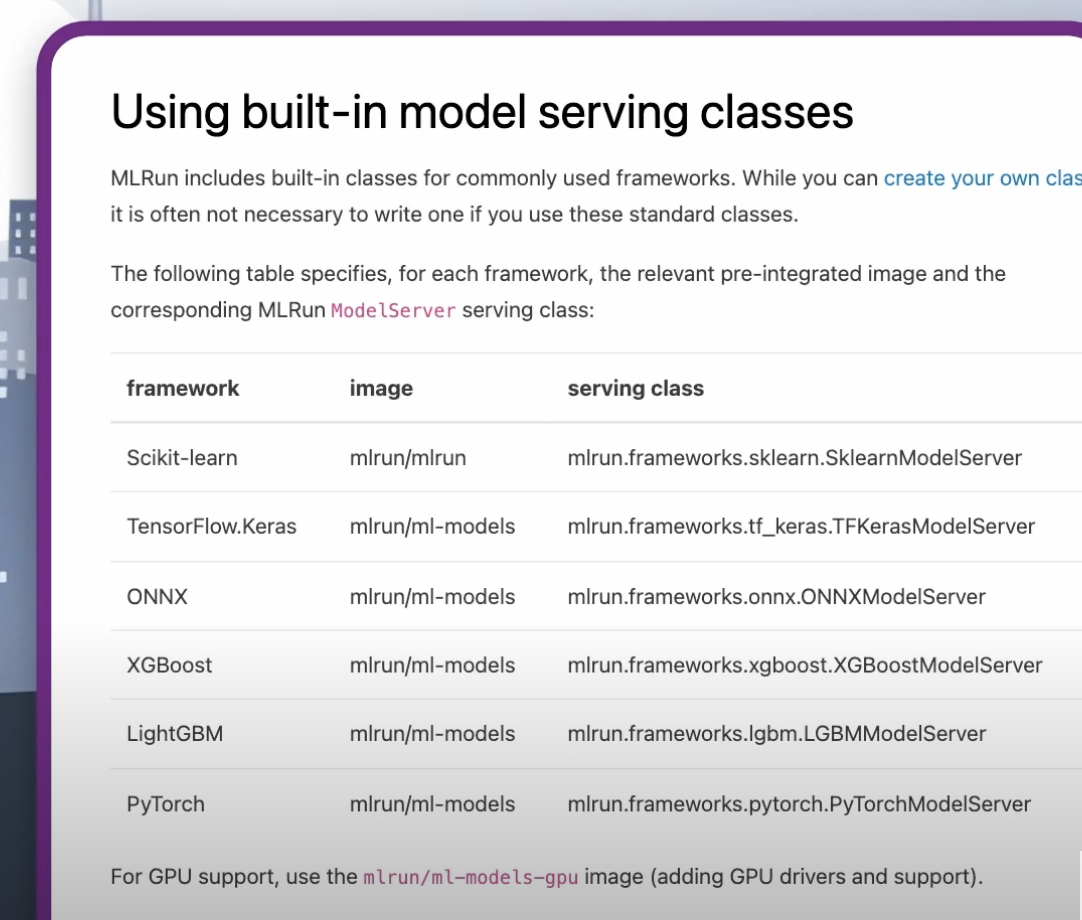
Or customize your own. You can read more about this in the docs.
The example below shows a simple, singular model. There are also more advanced models that include steps for data enrichment, pre-processing, post-processing, data transformations, aggregations and more.
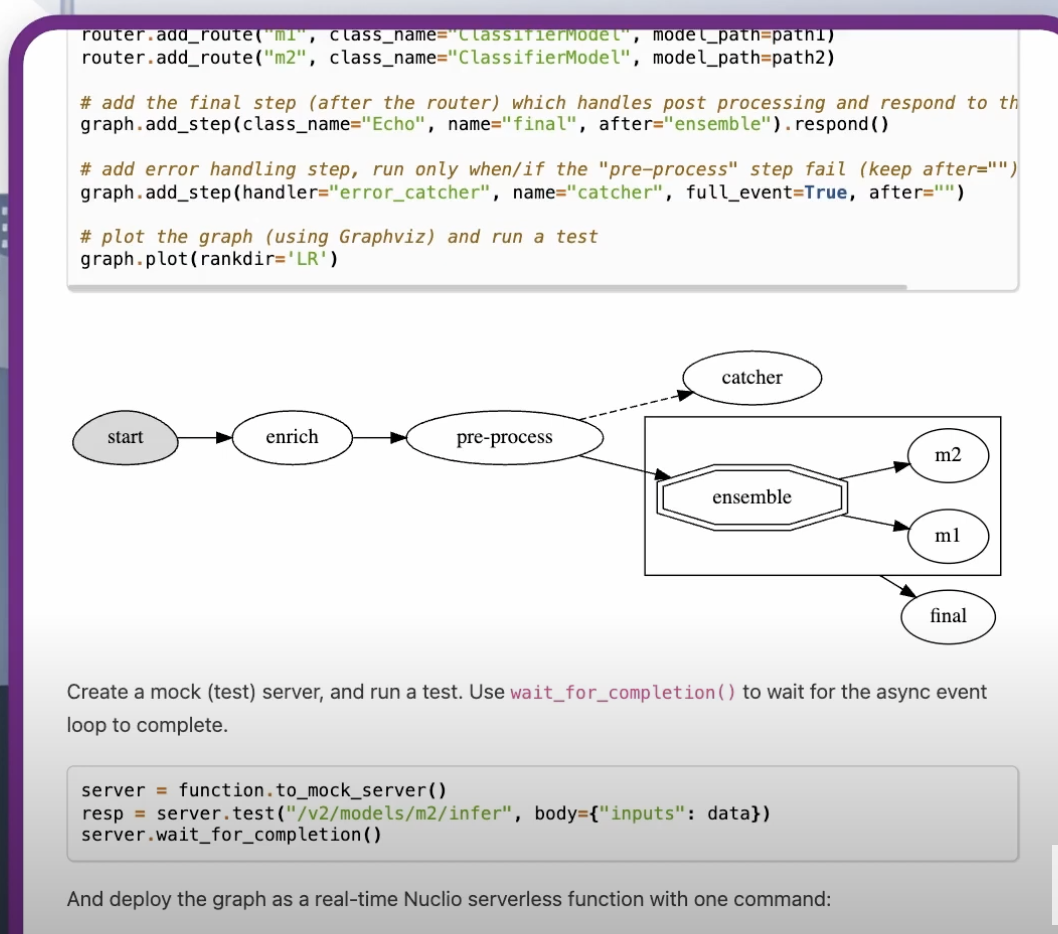
Read more about real-time serving here.
# Create a mock (simulator of the real-time function)
server = serving_fn.to_mock_server()
Use the mock server `test` method (server.test) to test the model server.
The last part of the code is the model server, which you can send data inputs to and acts exactly like a model server.
Finally, it’s time to deploy to production with a single line of code.
serving_fn.deploy()
This will take the code, all the parameters, the pre- and post-processing, etc., package them up in a container deployed on Kubernetes and expose them to an endpoint. The endpoint contains your transformation, pre- and post-processing, business logic, etc. This is all deployed at once, while supporting rolling upgrades, scale, etc.
That’s it! You now know how to use MLRun to manage and deploy ML models. As you can see, MLRun is more than just training and deploying models to an endpoint. It is an open source machine learning platform that helps build a production-ready application that includes everything from data transformations to your business logic to the model deployments to a lot more.
