Introducing MLRun Community Edition
MLRun CE is the out-of-the-box solution of MLRun for AI and ML orchestration and model lifecycle management.


MLRun Community Edition (CE) is the out-of-the-box solution of MLRun for AI and ML orchestration and model lifecycle management.
MLRun CE can be installed directly on your Kubernetes cluster or even on your local desktop. It provides a complete, integrated MLOps stack that combines MLRun’s orchestration power with Nuclio’s high-performance serverless engine, along with additional tools for data storage, monitoring, and more.
In this blog, we’ll explain how MLRun CE works and recommended use cases, and share how one of our users leverages MLRun CE for experiment and model tracking.
MLRun CE is ready to use out of the box. It is designed to simplify the entire lifecycle of LLM and ML projects, and provides a robust solution for complex MLOps needs (see examples below).
By easily installing the MLRun CE Helm chart on your Kubernetes cluster or local desktop, you get a powerful, integrated environment for development. The platform is built on two cores: MLRun for MLOps orchestration and Nuclio for serverless computing.
MLRun is the MLOps orchestration framework that automates the entire AI pipeline, from data preparation and model training to deployment and management. It automates tasks like model tuning and optimization, enabling you to build and monitor scalable AI applications. With MLRun, you can run real-time applications over elastic resources and gain end-to-end observability.
Nuclio is a high-performance serverless framework that focuses on data, I/O, and compute-intensive workloads. It is the engine that powers the real-time functions within MLRun. Nuclio allows you to deploy your code as serverless functions, which are highly efficient and can process hundreds of thousands of events per second. It supports various data sources, triggers, and execution over CPUs and GPUs. It also supports real-time serving for generative AI use cases.
MLRun CE easily integrates with several other tools. It includes an internal JupyterLab service for developing your LLM code and supports Kubeflow Pipelines workflow for creating multi-step AI pipelines. It also works with Kafka and TDengine for robust, real-time and batch model monitoring, and provides built-in support for Spark and Grafana for data processing and visualization.
Data and developer users of MLRun CE can benefit from:
Seamless Integrations: The platform integrates with a wide range of popular open-source tools, including Kubeflow Pipelines for workflow management, and Spark and Grafana for data processing and visualization. This open architecture gives you the flexibility to use the tools you already know and love.
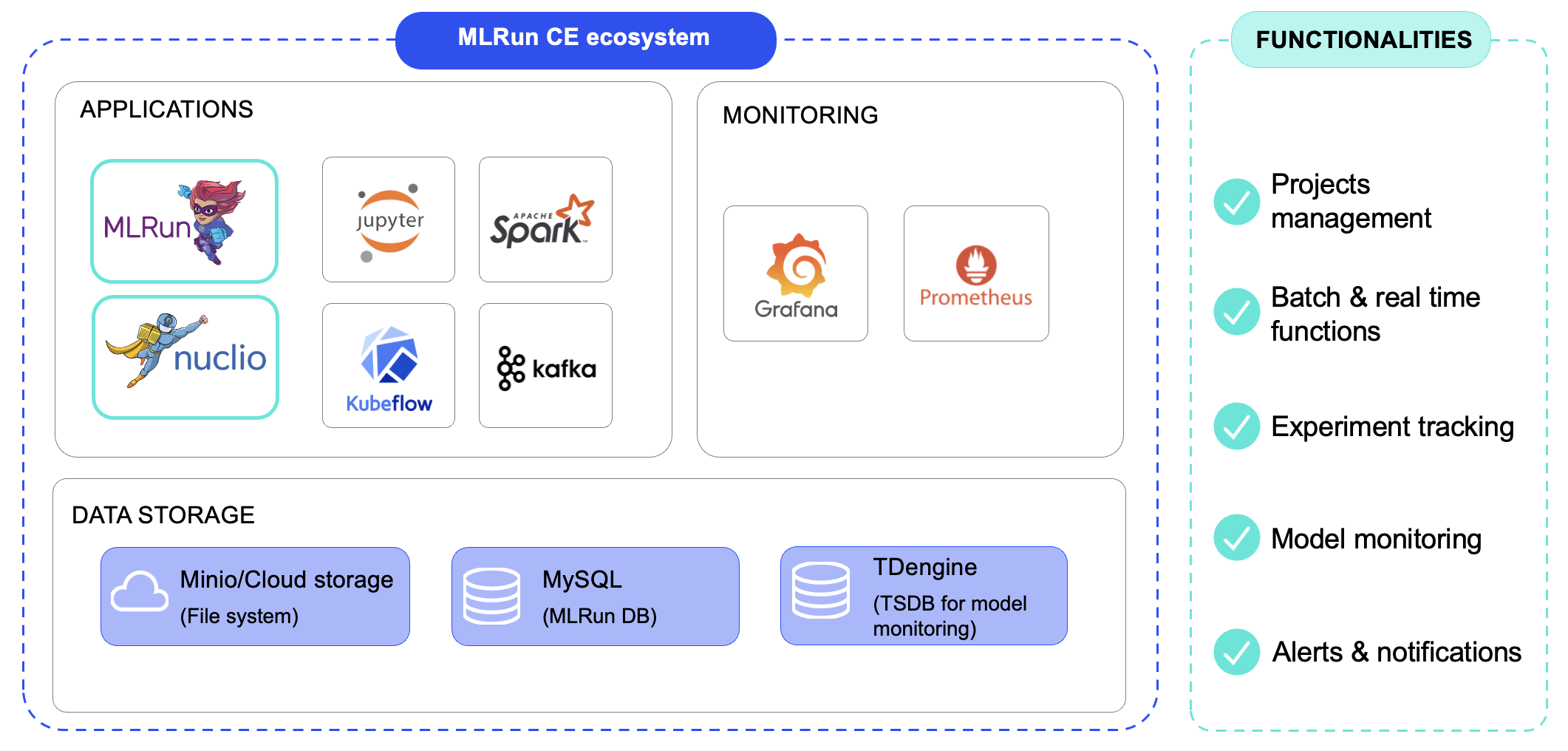
The following are the components that get installed when installing MLRun CE
The picture below describes the relations between them. MLRun is the orchestrator and deploy function by using MLRun, Nuclio, Spark and MPI jobs runtimes. Grafana is used to monitor usage, Jupyter for out-of-the-box development platforms and Minio, MySQL & TDengine to store data.
MLRun CE can be used for a wide variety of MLOps use cases. In particular:
One of our community users has adopted MLRun CE as their MLOps platform to deploy, track, and manage their ML training experiments and models. MLRun CE is deployed across Kubernetes environments.They run two main types of ML workflows run through MLRun CE. The first is manually triggered training jobs. MLRun CE runs the training function, logs metrics and datasets, and registers the model for deployment on edge devices.
The second is automated periodic insight models, such as drift detection functions that compare recent data against training distributions and generate alerts when anomalies occur.
The team relies on MLRun CE’s full set of components: project management, batch functions, experiment tracking, model monitoring, and alerts.
With MLRun CE, their data science teams can:
Check out these resources for more information:
