MLRun + NVIDIA NeMo: Building Observable AI Data Flywheels in Production
NVIDIA NeMo and Iguazio streamline training, evaluation, fine-tuning and monitoring of AI models at scale, ensuring high-performance, low latency and lowering costs


We’ve integrated MLRun with NVIDIA NeMo microservices, to extend NVIDIA’s Data Flywheel Blueprint. This integration lets you automatically train, evaluate, fine-tune and monitor AI models at scale, while ensuring low latency and reduced resource use. Read on for all the details:
NVIDIA NeMo is a modular microservices platform for building and continuously improving agentic AI systems.
It provides:
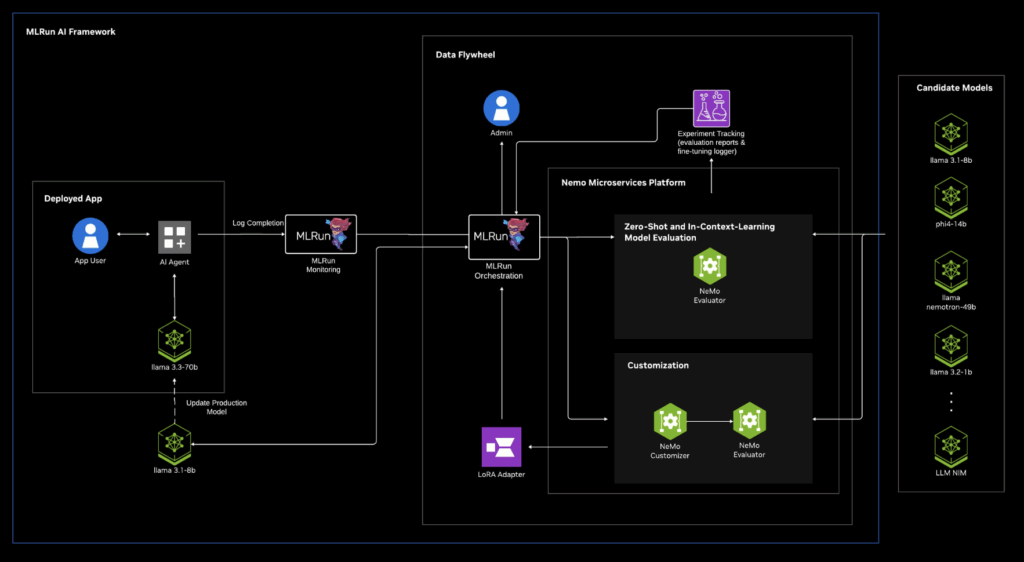
How the integration works:
Use case example:
Let’s say we want to improve a small model’s performance to match a larger model. The data Flywheel runs experiments against production logs against candidate models and surfaces efficient models that meet accuracy targets.
Explore the joint Iguazio MLRun and NVIDIA blueprint to try for yourself.
